Auto-DeepLab 정리
Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation
존스홉킨스 대학 A. Yuile 교수님 랩에서 PNASNet 이 나온적이 있는데, 그 저자가 CVPR 2019에 발표할 Auto-semantic segmentation 논문이다.
NAS, NASNet, PNASNet 등등 AutoML이 갈수록 practical해지고, 그 성능은 말할 것도 없다. 하지만 학습에대한 cost가 엄청난 탓에 그 동안 cifar-10 같은 작은 데이터에서만 학습을 진행하였고, classification 문제에 한정하여 연구가 진행되어왔다.
이제는 그러한 한계도 뛰어넘고 다양한 task로 확장되어가는 AutoML 인듯 하다.
1 Intro
먼저 그 동안 AutoML의 특징을 살짝 정리해보면,
- 기존 NASNet 이후 cell을 automated하게 설계 하고, 이 설계 된 cell을 이용하여 다시 큰틀에서 사람이 설계한다.
- cifar-10과 같은 작은 데이터를 이용해 어느정도 학습에대한 시간 부담을 줄임–> 하지만, classification domain에만 의존적이게 됨.
이 논문에서는, 이러한 한계를 넘고자 semantic segmentation을 수행하는 Neural Architecture를 search하는 방법은 연구했다.
- NAS에서는 transfer learning을 활용, low-resolution image로 학습시키고, high-resolution image에 적용함 (즉, cifar-10로 학습시키고 ImageNet에서 테스트함, 근데 SOTA….ㄷㄷ…)
반면 semantic segmentation은 본질적으로 high-resolution image에서 동작해야함, 이를 위해 필요한것:
- 더 높은 해상도로인해 생기는 architectural variations를 capture하기 위한 더 안정적이고 일반적인 search space.
- 더 높은 해상도는 더 큰 computation을 요구하므로 더 효율적인 architecture search technique.
일반적으로 CNN은 two-level hierarchy로 되어있다고함. : 1) spatial resolution을 조절하는 outer network, 2) layer-wise computation을 다루는 inner cell.
뭐 대략적으로 이해는가지만, 확 와닿지는 않는다.
암튼, 그동안 NAS같은것들은 inner cell만 집중하여 네트워크를 설계하였지, 결국 outer network는 사람이 손수 설계했다는 것이 이 논무에서 주장하는 기존 연구의 한계점이다.
그래서 이 논문은, 일반적으로 많이 사용했던 cell level search를 확장한 trellis-like network level search (격자구조의 network level search)를 제안하면서, hierarchical architecture search space를 구성한다.
아래 표를 보면, Auto-DeepLab은 cell 단위가 아닌 더 큰 Network 단위로 네트워크를 search하며, cityscape같은 상대적으로 큰 데이터로 상당히 짧은 시간 내 학습이 가능하게 되었다.
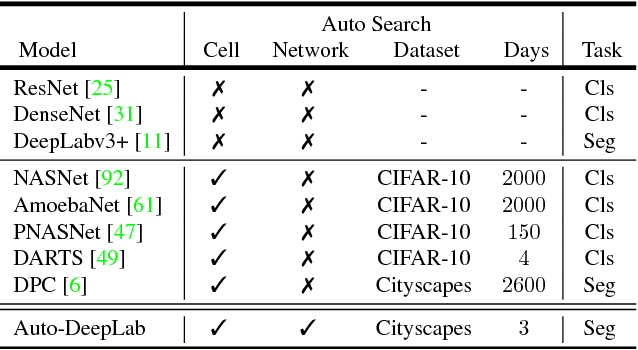
2 Related Work
Semantic Image Segmentation
생략
Neural Architecture Search Method
- Using policy gradient:
- B. Zoph and Q. V. Le. Neural architecture search with reinforcement learning. In ICLR, 2017.
- B. Zoph, V. Vasudevan, J. Shlens, and Q. V. Le. Learning transferable architectures for scalable image recognition. In CVPR, 2018.
- H. Cai, T. Chen, W. Zhang, Y. Yu, and J. Wang. Efficient architecture search by network transformation. In AAAI, 2018.
- M. Tan, B. Chen, R. Pang, V. Vasudevan, and Q. V. Le. Mnasnet: Platform-aware neural architecture search for mobile. arXiv:1807.11626, 2018.
- Using Q-Learning:
- B. Baker, O. Gupta, N. Naik, and R. Raskar. Designing neural network architectures using reinforcement learning. In ICLR, 2017.
- Z. Zhong, J. Yan, W. Wu, J. Shao, and C.-L. Liu. Practical block-wise neural network architecture generation. In CVPR, 2018.
- Using EA (Evolutionary algorithms):
- E. Real, S. Moore, A. Selle, S. Saxena, Y. L. Suematsu, J. Tan, Q. Le, and A. Kurakin. Large-scale evolution of image classifiers. In ICML, 2017.
- L. Xie and A. Yuille. Genetic cnn. In ICCV, 2017.
- R. Miikkulainen, J. Liang, E. Meyerson, A. Rawal, D. Fink, O. Francon, B. Raju, H. Shahrzad, A. Navruzyan, N. Duffy, and B. Hodjat. Evolving deep neural networks. arXiv:1703.00548, 2017.
- H. Liu, K. Simonyan, O. Vinyals, C. Fernando, and K. Kavukcuoglu. Hierarchical representations for efficient architecture search. In ICLR, 2018.
- E. Real, A. Aggarwal, Y. Huang, and Q. V. Le. Regularized evolution for image classifier architecture search. arXiv:1802.01548, 2018.
PNASNet - 이 논문 저자가 제안한 Progressive NASNet, cost는 상당히 줄이면서 정확도는 유지함.
Neural Architecture Search Space
2017년 처음 발표된 NAS 나, 진화알고리즘을 사용한 Amoeba나 모두 전체 네트워크를 layer 하나씩 만들어갔다. 당연히 매우 매우 매우 느림…. 하지만 최근 연구들은 반복되는 cell 구조를 serach하는 방식으로 연구가 진행되었더니 조금이나마 time cost 문제를 해소할 수 있었다. 근데 여기서 outer network 이런 cell을 stacking하는 과정은 수작업으로 이루어지게됨. 이런 접근 방법은 NASNet [B. Zoph et al., 2018]에서 CNN의 two-level hierarchy 구조에 영감을 받아 제안됬다.
이 논문에서도 여전히 기존 연구들과의 일관성을 유지하기 위해 cell 단위의 search space를 사용하게 된다. 그러나 two-level hierarchy를 통합하여 serach하기 원하기 때문에, 새로운 network level search를 제안한다. 여기서 제안하는 구조는 보기에는 2016년 NeurIPS에 발표된 “Convolutional Neural Fabrics “ 라는 논문과 유사하지만, Convolutional Neural Fabrics 에서는 network를 바꾸려는 의도 없이 전체 fabrics를 유지하고 이 논문에서는 각 connection에 명식적으로 weighting을 해주고 개별 구조를 decoding 하는데 초점을 둔다.
추가적으로, semantic segmentation network를 search한다는 것이 2018 NerurIPS에 발표된 DPC와 유사하지만, DPC는 ASPP module만 search한 반면, 여기서는 좀 더 fundamental하게 network backbone architecture를 search하는데 초점을 두었다.
3 Architecture Search Space
여기선 많은 인기 있는 design의 observation과 summarization 을 기반으로 새로운 search space를 제안한다.
Cell Level Search Space
- cell - small fully convolutional module (이 cell 이 여러번 반복되게 된다.)
- cell 은 B개의 Block으로 구성된 acyclic graph
- 각 Block은 two-branch 구조, 2개의 input을 받아서 1개의 output을 내는 형태
- cell 내 Block 은 5-tuple 로 구성되엉 있음 (아래 그림 처럼 NASNet과 완전 동일한듯)

- 한 cell의 output , 결국 B개의 block들 에서는 이 나오고 이게 모두 concat됨, 그러므로, cell에 더 많은 block들이 추가 되면 다음 block은 잠재적으로 입력으로부터 더 많은 선택권은 갖게 되는것임.

여기까지 설정은 뭐 완전히 NASNet과 동일한듯 하다. 대신 segmentation을 위해 operation 의 선택지가 특별히 다음과같이 8개로 정의된다:
- depthwise-separable conv
- depthwise-separable conv
- atrous conv with rate 2
- atrous conv with rate 2
- average pooling
- max pooling
- skip connection
- no connection (zero)
마지막은 두 로 각각 연산된 두 결과를 합치는 는 오직 element-wise addition으로 제한한다.
Network Level Search Space
기존 NASNet에서는 한번에 한 cell structure를 찾음, 그리고 전체 network구조는 미리 정의됨 (cell들을 어떻게 stacking할지). 결국 전체 network구조는 search의 대상이 아니었다.
그리고 미리 정의된 network의 구조는 몇개의 normal cell (spatial resolution은 보존)과 reduction cell (spatial resolution을 반으로 줄임) 들로 이루어져있다. 이런 keep-downsampling 전략은 image classification에서는 타당하게 이용된다. 그러나 dense image prediction (pixel wise classification : segmentation) 같은 작업에서는 high spatial resolution을 유지하는것이 상당히 중요하다.
이런 dense image prediction을 위한 다양한 network 구조들 사이에서, 일관되야하는 두 가지 원칙은:
- 다음 layer의 spatial resolution은 두배가 커지거나, 두배가 작아지거나, 그대로 유지된다.
- 가장 작은 spatial resolution은 32배로 작아지는 것이다.
먼저 network의 시작은 two-layer “stem” 구조로 이루어지는데, 이 “stem” 구조는 각각 spatial resolution을 두배 줄인다. 그리고나서, 알려지지 않은 spatial resolution을 가지는 총 L개의 layer…..뭐라는거야 그림이나 보자
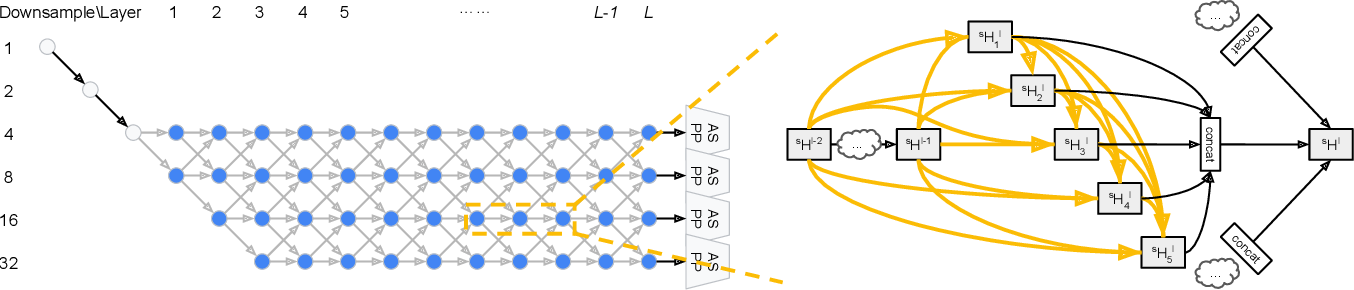
왼쪽 그림을보면, 총 L개의 layer를 쌓는것을 볼 수 있다. 이 논문에서는 L=12로 설정했다고 한다. 여기서 회색 노드들은 “고정된 stem” 이다. 이렇게 각 노드가 2개의 선택지가 주어지면서 하나씩 선택해 나가는 식으로 결정되고 L번째까지 선택되면 network 구성이 완료되는 것 같다. 오른쪽 그림은 serach중에, 각 cell이 densely하게 connect 된다는 것을 보여준다. 모든 노란색 화살표들은 와 연관 되고, concat 이후 3개의 검은 화살표는 각각 과 연관된다.
여기서 는 뒤에 나올것임, 일단 기존에 semantic segmentation을 위해 디자인된 popular network들을 위와 같은 격자구조형식으로 나타내면 아래 그림처럼 된다.

첫번째껀 DeepLab V3, 두번째꺼는 DeconvNet, 세번째꺼는 Stacked Hourglass network 이다.
뭐 이런식으로 일봔화가 가능하다라는 것을 어필하고 싶었던듯… 암튼 이렇게 network 구조를 search하게 되어서 더 challenging하고 이전 NAS 방식 보다 일반화되었다고 주장한다.
4 Methods
여기서는 discrete한 구조를 continuous relaxation 하는 걸 소개하면서 어떻게 optimize하여 최적의 구조를 찾는지, search가 끝난후 어떻게 다시 descrete하게 decode하는지 설명한다.
Continuous Relaxation of Architectures
Cell Architecture
DARTS [H. Liu et al., 2018] 에서 소개됬던 continuous relaxation 을 다시 사용한다.
모든 block의 output tensor인 는 내 모든 hidden state 와 연결된다:
그리고 를 continuous relaxation을 통해 로 근사한다:
여기서,
는 결국 relaxation을 하는 가중치인듯 하다. 나름대로 정리를 해보자면 layer 에서 layer 로 갈때, k개의 operation을 통과하고 여기서 통과된 output 들에 가중치를 주어서 summation을 하는 듯 ??? 암튼 는 softmax 통해서 쉽게 구현 가능하다고 한다.
그리고 input이되는 는 이전 cell의 output 또는 전전 cell의 output 에서 가져오므로, 식을 정리하자면 다음과 같다:
이부분은 DARTS를 읽어봐야 이해가 될듯하다… 뭐 어떤식으로 연결되는건지 감이안옴;;
Network Architecture
continuous relaxation을 하기위해서, 각 layer 은 이와 같이 4개의 hidden state를 가지게됨. 왼쪽 upper subscript는 spatial resolution을 의미
이렇게 search space를 정확히 match하기 위한 network level의 continuous relaxation을 정의한다 :
여기서 이고 근데 여기서 의 subcript에서 화살표가 반대가 아닌가 싶다.
이해한대로 정리해보면, spatial resolution을 2배 늘릴지, 2배 줄일지, 그냥 유지할지 이 세가지 선택지를 를 통해서 가중치를 주며 outer network를 설계하는 것 같다.
마지막에는 가능한 모든 resolution에 ASPP (Atrous Spatial Pyramid Pooling) 모듈을 붙인다.
Optimization
위에서 설명한 continuous relaxation의 장점은 각 연결들의 강도를 조절하는 scalar 를 도입했기때문에 미분이 가능하다는 것이다!! –> Gradient Descent를 통해서 효율적으로 학습가능하다!!
1차 근사 (first-order approximation, 테일러급수 말하는듯) 를 사용하고, 다음과 같이 데이터셋을 , 로 분리하여 학습된다:
- 에 의해서 네트워크 내 파라미터인 업데이트
- 에 의해서 업데이트
Decoding Discrete Architecture
Cell Architecture - DARTS와 동일하게 하는듯, 각 block에 대해 가장 큰 2개의 predecessor로 결정 (, 여기서 의 뜻은 no connection)
Network Architecture - 각 path들의 connection weight는 서로다른 layer에 따른 spatial resolution들 사이 trasition probability라고 할 수 있음 (각 state는 3개의 transition probability를 가짐: 2배 커질 확률, 2배 작아질 확률, 그대로 유지할 확률). 여기서 layer들을 time 으로 보았는데, 여기서 시작부터 끝까지 probability가 최대가 되는 path를 찾기 위해서, classic Viterbi 알고리즘을 사용해서 path를 찾아내는식으로 다시 descrete하게 디코딩함.
가장 큰 novelty는 outer network까지도 search 한다는 것 같은데, 일단 실용적으로 시간을 줄이는 것은 기존에 DARTS에서 제안된 것처럼 강화학습과 진화알고리즘 같은 것을 사용하지 않고, continuous relaxation을 사용하여 gradient descent를 적용한 것이 큰 역할을 한것 같다 (DARTS를 먼저 읽어보면 더 명확히 이해할 수 있을듯).
Reference
[1] C. Liu, L.-C Chen, F. Schroff, H. Adam, W. Hua, A. Yuile, and L. Fei-Fei, “Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation”, In CVPR, 2019 [pdf]