OCR (Optical Character Recognition) 개념 정리
OCR (Optical Character Recognition)
Intro
OCR (Optical Character Recognition) 은 deep-learning을 요구하지 않는 측면이 있기 때문에, 가장 먼저 다뤄진 computer vision task 중 하나이다. 그렇기 때문에 딥-러닝 붐이 일어난 2012 이전에 다양한 OCR 방법들이 존재했다.
이런것들이 OCR 문제들은 이미 “해결”되었다, 더 이상 challenging하지 못하다라고 생각하게끔 만들었다. 비슷한 맥락으로 딥-러닝이 필요하지 않다고 믿기도 한다. 다른말로는 딥-러닝을 OCR에 적용하는 것은 지나친것이라고도 한다.
Computer vision, machine learning을 하는 사람들은 일반적으로 해결된 task는 없고, OCR도 마찬가지라는 것을 알고있다. 반대로, OCR은 매우 specific한 사례에서만 매우 좋은 결과를 내고 있고, 여전히 challenging한 문제로 여겨지고 있다.
추가적으로, OCR task에 대해 딥-러닝을 사용하지 않는 좋은 해결법이 있다는 것은 맞다. 하지만, 더 개선하기 위한 발걸음으로, 더 일반화된 해결법으로 딥-러닝은 필수가 될 것이다.
Type of OCR
먼저 힌트를 하나 주자면, OCR은 다양한 의미를 가진다. 먼저 가장 일반적인 의미로는, 모든 가능한 image로부터 text를 추출하는 것이다. 예를들자면, 책에서 프린트 되어있는 글자 또는 graffiti가 있는 어떠한 image같은 경우에서 말이다. 이외에도 license plates, no-robot captchas, street signs 등 여러 task들을 찾을 수 있다.
OCR task들의 속성들은 아래와 같이 나타난다:
- Text density: 프린트가 된 page위에, text가 빽빽(dense)하게 있다. 그러나, 하나의 표지판만 존재하는 거리 image 같은 경우는 text가 듬성듬성(sparse) 있다.
- Structure of text: page에 존재하는 text는 대부분 줄에 맞춰진 구조적 성향을 가진다. 그 반면에, wild하게 있는 text는 모두 다른 rotation이 있을 수 있다.
- Fonts: 프린트 된 font들은 noisy한 손글씨보다 좀 더 구조적인 성향을 가지기 때문에 비교적 쉽다.
- Character type: text는 서로 다른 사람들로 부터 서로 다른 언어로 표현될 수 있다. 추가적으로, text의 구조가 house number 같이 숫자들과 다를 수 있다.
- Artifacts: 외부로 찍은 사진은 스캐너로 스캔한 것 보다 더 많이 noisy하다.
- Location: 몇 가지 task들은 crop하고 중앙에 text를 위치하게 하는 걸 포함하는 반면, text는 image내에서 random한 위치에 나타날 수 있다.
Datasets / Tasks
SVHN (The Street View House Numbers) Dataset
가장 먼저 시작하기 좋은 데이터셋은 [SVHN][http://ufldl.stanford.edu/housenumbers/]이다. 이름에서 알 수 있듯이, google street view를 통해서 추출한 house number들로 이루어진 데이터셋이다. 난이도는 중간 정도이다. 여기서 숫자들은 다양한 모양과 다양한 writing style을 가질 수 있는데, 각 house number는 image 중앙에 위치하기 때문에 따로 detection이 필요하지 않다. 각 Image들은 매우 고화질이 아니고 배치가 조금 특이할 수 있다.
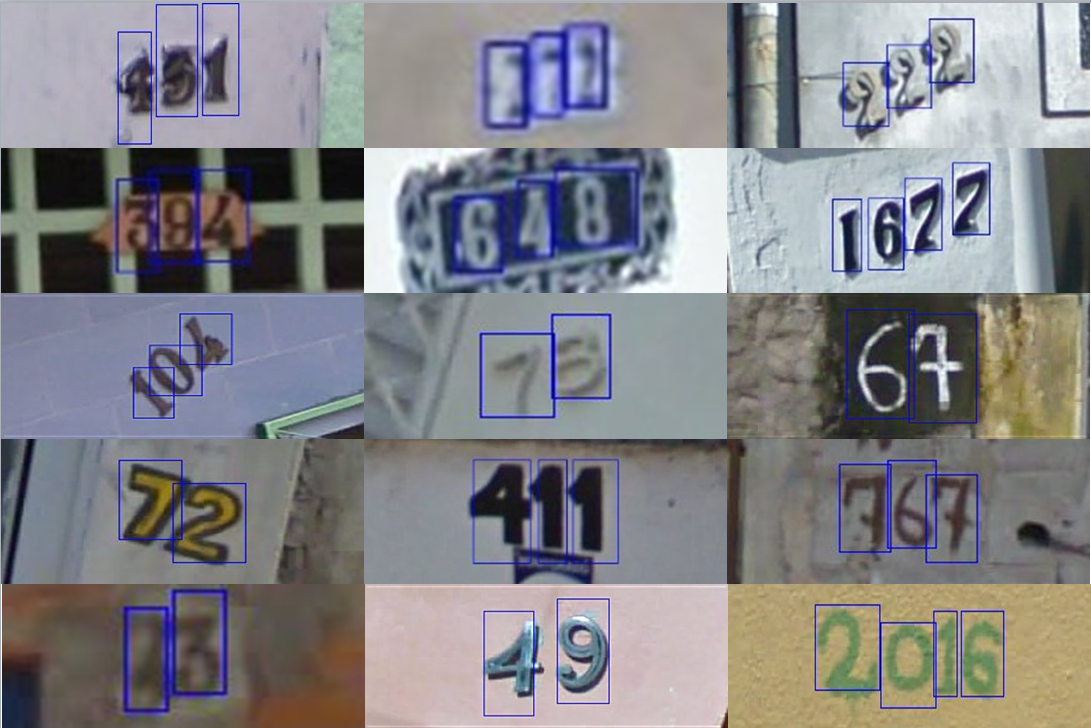
License plate
또 따른 많이 어렵지 않고 실용적인 challenge로, 번호판 인식 (license plate recognition)가 있다. OCR 분야에서 가장 많이 수행되는 task로, 번호판을 detection하고 문자들을 인식한다. 번호판의 모양이 비교적 일정하기 때문에, 실제 번호를 인식하기전에 간단히 reshape하는 방식을 사용하기도 한다.

다음 웹사이트에서 몇가지 예시를 확인할 수 있다:
- [OpenALPR][https://github.com/openalpr/openalpr] 은 딥-러닝이 사용되지 않은 방식으로, 다양한 나라의 번호판을 인식하는 매우 robust한 tool이다.
- https://github.com/qjadud1994/CRNN-Keras : CRNN 모델을 활용하여 한국 번호판을 인식 (Keras)
- [Supervise.ly][https://towardsdatascience.com/number-plate-detection-with-supervisely-and-tensorflow-part-1-e84c74d4382c]
CAPTCHA
인터넷에 로봇들이 너무 많기 때문에, 실제 사람과 구분하기 위해 vision task를 사용하는데, 정확히는 text를 읽게하는 방식을 사용한다. 이것이 바로 CAPTCHA이다. 이 많은 text들은 computer가 읽기 어렵게하기 위해 random하게 나오고 distortion이 존재하는 형태이다. 하지만, 요즘은 이런 CAPTCHA를 푸는게 그리 어렵지는 않다…(딥-러닝 때문인것 같다.)
실제 딥-러닝으로 CAPTCHA를 푸는 [tutorial][https://medium.com/@ageitgey/how-to-break-a-captcha-system-in-15-minutes-with-machine-learning-dbebb035a710]도 존재한다.

PDF OCR
OCR 에서 가장 일반적인 시나리오는 printed/pdf OCR이다. 프린트된 문서의 구조적인 특성은 text 같은 걸 parsing하는데 더 쉽게 만들어 준다. 대부분 OCR tool들(e.g. Tesseract)은 이런 문제들을 다루기위해 많은 시도를 하였고 설공적인 결과를 가져왔다.
OCR in the wild
이게 가장 challenging한 OCR task가 아닐까 싶다. 일반적으로 computer vision 분야에서 chanllenging하게 다뤄지는 noise, lighting, artifact 같은 것들이 함께 나타난다. 몇 가지 이런 것들과 연관 된 데이터로는 coco-text, SVT 같은 데이터셋들이 있다. 이런 데이터들은 그냥 street view 에서 text를 추출하는 형태로 이루어져있다.

Synth text
SynthText 는 데이터셋은 아니고 task 조차도 아니지만, training 효율을 개선하는 좋은 아이디어중 하나로 인공 적인 데이터를 생성하는 방법이다. 이미지에 주어지는 random한 문자 또는 단어는 flat한 특성 때문에 다른 object들 보다 더 자연스러워 보일 것이다.
우리는 CAPTCHA나 번호판 같은 쉬운 task들에 대해 데이터를 생성하는 것을 보았다. Wild 환경에서 데이터를 생성하는 것은 약간 더 복잡하다. 이미지의 depth 정보를 고려해야하는 것이 포함되는데, 운좋게도, SynthText는 앞에서 언급한 annotation들과 함께 이미지를 가져오고, 단어를 지능적으로 이미지위에 뿌려버리는 멋진 work이다. 진짜 같고 실용적인 text를 만들기 위해, SynthText 라이브러리는 두 개의 마스크를 가지고 있다. 하나는 depth 나머지 하나는 segmentation이다. 어떤 이미지에 사용하고 싶다면, 이 두 마스크 정보를 추가하는게 좋을 것이다.
SynthText repo: https://github.com/ankush-me/SynthText

MNIST
진짜 OCR task는 아니지만, MNIST를 제외하고 OCR에 대해 논하는것은 불가능하다. MNIST는 computer vision에서 가장 잘알려진 task이다. 그러나 10개의 숫자 중 한번에 하나의 숫자만을 인식하기 때문에 OCR 과 같다고 할 수는 없을 것 같다. 그러나, 이런 점들이 왜 OCR이 쉽게 여겨지는지 힌트가 될 수 있다. 추가적으로, 모든 letter들을 분리해서 detection하는 방법이 있기도 하고 그런면에서 MNIST 모델은 연관이 있다고 할 수 있다.

Strategies
위에서 어느정도 보았듯이, text recognition은 크게 두 단계로 나누어 진다.
먼저 Image 내에서 text들의 외형을 detection한다 –> 이것들은 dense할 수도 있고 sparse할 수도 있다. line/word 레벨에서 detection을 한 다음 우리는 다시 몇 가지 해결법으로 부터 선택을 해야하는데 크게 3가지로 구분한다:
- Classic computer vision techniques (전통적인 컴퓨터 비전 기술/알고리즘)
- Specialized deep learning
- Standard deep learning approach (Detection)
하나씩 살펴 보도록 하자
1. Classic computer vision techniques
일반적인 classic CV 방법은 일반적으로 다음과 같다:
- background로 부터 문자가 튀어나오듯이 돋보이도록 filter 들을 적용
- 문자들을 하나하난 인식하기 위해 contour detection 을 적용
- 어떤 문자인식 식별하기 위해 image classification 을 적용
만약 2번 항목이 잘된다면, 3번 항목은 pattern matching이나 machine learning 기법을 사용해 쉽게 쉽게 풀 수 있다.
그러나, contour detection은 일반화에 있어서 꽤 challenging 한 문제이다. 수동적인 fine-tuning이 많이 필요하기 때문에 대부분의 문제들에서 실행불가능하게 된다. 예를들면, 간단한 알고리즘을 SVHN 데이터에 적용한다고 하면 아래와 같이 좋은 결과를 얻게된다:


하지만 다음과 같이 두 문자가 붙어있는 경우 제대로 분리되어 detection 되질 않는다:


몇 가지 파라미터들을 만지작 거리기 시작하면 에러같은 것들을 조금은 줄일수 있을것이다. 하지만 불운하게도 다른 것들을 야기하게 된다. 다른말로, task가 쉬운 것이 아니라면, 이러한 방법들은 적합하지 못하다.
- Specialized deep learning approaches
성공적인 딥-러닝 방법들 자체가 워낙 범용성이 있기때문에 어느정도 OCR 을 풀 수 있었지만, 위에 언급된 속성들을 고려하면, OCR에 specialize된 네트워크가 매우 실용적일 수 있다.
아래 몇가지 예를 살펴보자.
EAST
EAST (Efficient Accurate Scene Text Detector) 는 text detection을 수행하는 간단하지만 강력한 방법이다. 이 방법은 OCR 에 specialize 된 네트워크를 사용했다. 사실 text recognition까지 해주지는 못하고 detection만 수행하지만 워낙 잘되기 때문에 충분히 언급할 가치가 있다.
또 다른 장점으로는 open-CV 라이브러리에 추가가 되어있기 때문에 매우 손쉽게 사용할 수 있다. (open-CV 4.0 이상부터 지원 하는것 같다.)
사실 네트워크는 잘 알려진 세그멘테이션 네트워크인 U-Net의 한 버전이다. 논문에서는 feature를 추출하는데 PVANet이 사용 되었지만 open-CV에서 제공 되는 라이브러리의 코드를 보면 그냥 ResNet을 사용하였다.

마지막으로, 출력으로는 rotation 된 bounding box로 두 가지 타입이 있다:
일반적으로 회전된 바운딩 박스($2\times 2+1$ 개의 파라미터) 또는 “quadrangle” 인데, 이건 바운딩 박스의 모든 꼭지점들의 좌표를 가지게 된다.

만약 현실에서 위와 같은 이미지가 있다고 하면, text를 인식하는 것은 큰 노력을 필요로 하지 않을 거다. 하지만, 실제 결과를 보면 완벽하다고는 할 수 없다.
CRNN
Convolutional-Recurrent Neural Network 는 2015년에 발표되었다. CNN과 RNN의 하이브리드한 접근 방식으로 end-to-end 하게 설계되어, 3단계로 단어들을 캡쳐하는 방식으로 시도되었다.
Key idea로는 첫번째 단계에서, 일반적인 fully-convolutional network로 이루어져있으며, 마지막 layer에서 나온 feature들의 column을 분리한다. 아래 그림을 보면 각 feature column들이 text에서 어떻게 확실한 section들을 나타내기 위해 시도했는지 볼 수 있다.

그 다음에, feature column들이 deep bi-directional LSTM으로 squence하게 들어가게 되고 문자들 간에 관계를 찾기 위해 시도한다. 출력은 sqeuence한 문장이나 단어가 된다.

마지막 세번째 단계로, transcription layer이다. 윗 단계에서 나온 sequence를 보면 중복되는 부분과 공백이 있는 등 상당이 지전분 할것이다. 이런 부분들은 probabilistic한 방법 들을 사용하여 통합하고 이해가 되는 seqence로 정제 시킨다고 생각하는 layer라고 보면 될것 같다.
이 방법은 CTC loss 라고 불리며 더 자세한 것은 여기를 참조하면 좋을 것 같다.
STN-net / SEE
SEE - Semi Supervised End-to-End Scene Text Recognition 은 Christian Bartzi 라는 분이 연구하신 결과인데, 완전히 text를 detection하고 recognition하는 부분을 end-to-end하게 만들었다.
여기서는 weak supervised (semi-supervision 와 같은 의미, 혼용 되어 사용되는 듯) 방식으로 학습을 하게 된다. 학습을 할때 오직 text 내용에 대한 annotation만 주어지고 bounding box에 대한 annotation은 주어지지 않는다. 이렇게하면 annotation에 대한 부담이 줄기 때문에 더 많은 데이터를 활용 할 수 있지만, 이런 데이터를 활용해서 학습을 시킨다는 것은 상당히 어려운 주제이고 이 논문에서는 그것들에 대해 토의하고 몇 가지 trick들을 통해 실제 이런 방식으로 학습이 가능하게 하였다.
SEE 를 발표하기전 먼저 STN-OCR 이라는 네트워크를 발표했었는데, SEE는 STN을 좀더 다듬고 일반성을 강조한 것이라고 생각하면 될 것 같다.

STN-OCR 은 이름에서 보이 듯이 딥-마인드에서 2015년에 발표한 Spatial Transformer Network 을 사용하였다. (최근 나온 Google Transformer 와는 다르다고 함.)
먼저 두개의 concatenate 된 네트워크들을 학습시키는데, 첫번째 네트워크는 이미지의 transformation을 학습하는 transformer이고, 다른 하나는 text를 인식하기 위한 LSTM으로 이루어져 있다.
저자들은 ResNet을 두번이나 사용하면서 ResNet의 “strong”한 propagation의 중요성을 상당히 강조했다.
3. Standard deep learning approach
위에서 많이 설명했지만, “단어”를 detection 하는데 일반적으로 많이 사용 되는 deep learning 기반의 detector들 (SSD, YOLO, Mask-RCNN 등) 을 사용할 수 있다. 이러한 네트워크들에 대한 자료는 인터넷에 많으므로…생략….
해당 글은 Reference 원문은 그냥 내 입맛에 맞게 옮기 것이므로 실제 예제나 추가적인 정보는 Reference를 참조하길 바란다.
Reference
[1] Towards Data Science: A gentle introduction to OCR by Gidi Shperber