DeepLab V2 정리
DeepLab V2
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs (Conditional Random Fields)
Intro
DCNNs (Deep Convolutional Neural Networks) 기반 semantic segmentation 의 3가지 challenge:
- Feature resolution을 줄이는 것.
- 다양한 scale의 object들의 존재
- DCNN의 Invariance 문제 때매 localization 정확도가 주는 문제
DeepLab 시스템에서는 위와 같은 문제를 해결하고자 한다.
첫번째 문제는 반복되는 downsampling (max-pooling) 에 의해서 일어난다 (‘striding’ 이라고 하는 문제인듯). FCN (Fully Convolutional Network)을 사용할 경우 spatial한 resolution들이 반복되는 downsampling을 거치면서 줄어들게 된다.
- 이런 문제를 해결하기 위해 여기서는 마지막 몇 개의 max-pooling 단계에서 downsampling 을 수행하지 않는다.
- 대신에 upsampling을 진행함 , 결과적으로 높은 sampling rate로 계산 된 feature map이 나옴
- Filter upsampling은 nonzero filter tap들 사이 inserting holes와 마찬가지인데, 이딴 기술은 신호처리나, wavelet transform 같은데 오래전부터 사용 되면서 “algorithme a trous” 뭐이 따구로 알려져있음 (trous는 hole)
- atrous convolution 을 사용함 –> upsampling 할라고 사용하는 것
- atrous convolution을 적용하면서 full resolutiond을 되찾음 –> 기존 deconvolutional layer를 대체 가능
- atrous convolution의 장점으로 넓은 receptive field를 아우르면서 파라미터수는 크게 증가하지 않는 다는것
두번째 문제는 다양한 scale의 object들이 존재하는 것인데, 일반적으로는 rescale된 버전의 DCNN을 적용, 이런 방식이 지네가 제안한 시스템에서도 성능을 향상시키지만, computing cost가 상당함
- Spatial pyramid pooling에 영감을 받아, comtationally efficient한 resampling 구조를 제안
- 여러개의 다른 sampling rate를 가지는 atrous convolution layer 병렬적으로 이용하여 구현함 –> “atrous spatial pyramid pooling” (ASPP) 라고 명명
세번째 문제는 object 중심의 classifier가 spatial transformation에 invariance를 요구한다는 문제. 이건 사실 DCNN의 본질적인 문제인데, skip-layer를 사용해 “hyper-column” feature를 추출하므로써 조금 완화가능
- 여기서는 fully-connected Conditional Random Field (CRF) 를 사용하여 훨씬 더 효과적인 접근법 제안
- CRFs는 원래 semantic segmentation에서 널리 사용되왔음 –> 여기서도 그냥 가져다 쓴건듯
- 암튼 이거 써서 성능을 개선했음
Methods
Atrous Convolution for Dense Feature Extraction and Field-of-View Enlargement
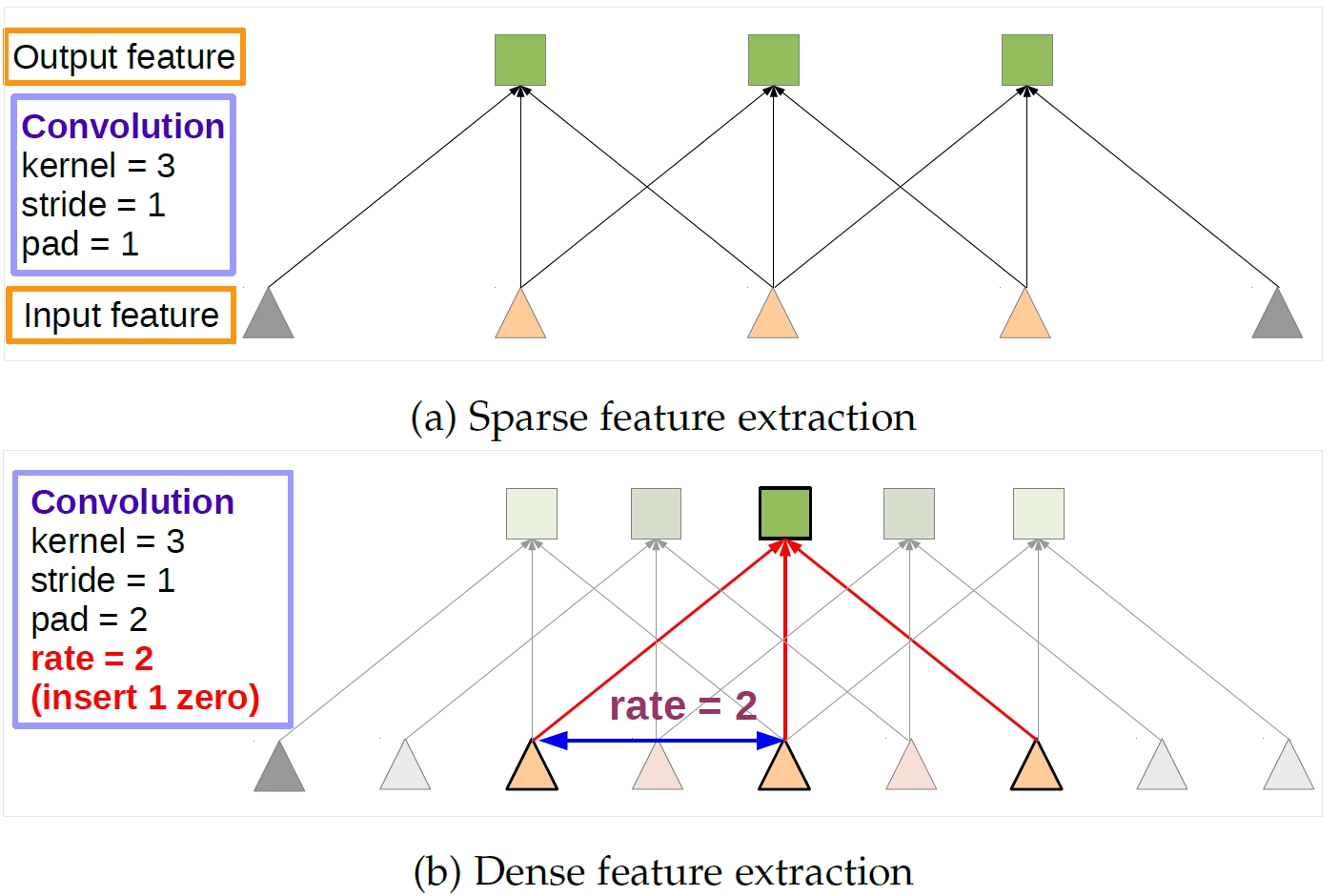
그냥 convolution이 아니라 atrous convolution을 사용.
1-dimenstion의 신호 를 input으로 받아 를 출력하는 예를 들어 생각해보면 :
는 filter이고 는 전체 filter 길이, 은 rate parameter로 일반적인 convolution은 이다.
아래 그림이 1-D atrous convolution의 예시
아래 그림은 일반 convolution에서 upsampling을 진행한것과 atrous convolution을 진행한 것과의 차이
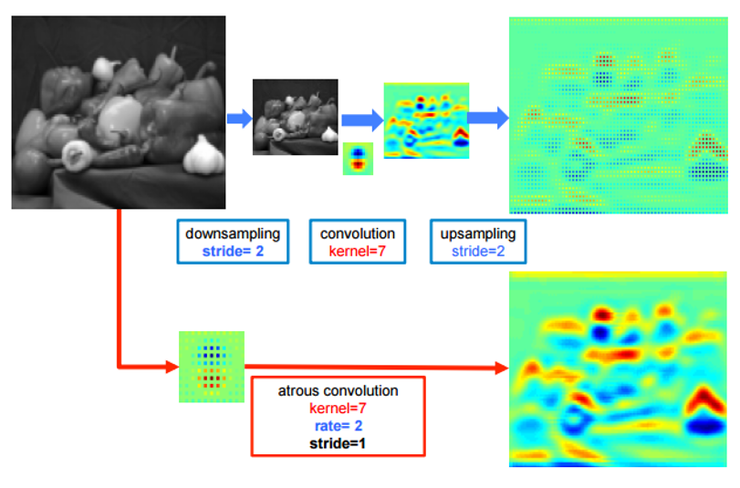
확실히 atrous convolution을 사용한 것이 복원력이 좋다!
ResNet-101이나 VGG-16에서 convolution이나 pooling 이 resolution을 저하시키는걸 조금이나마 방지할라고 stride를 1로 설정한다. 그리고 모든 convolution을 atrous convolution () 로 대체.
이렇게 함으로써 original image resolution의 feature를 계산할 수 있다! 근데 이건 사실 너무 많은 cost가 소모됨.
그래서 여기선 이런 방식 대신 Hybrid 방식을 도입, 이게 뭐시냐면 atrous convolution을 적용하여 계산된 feature map의 density를 4배를 증가 시킴, 그리고 바로 fast bilinear interpolation을 적용하여 feature map의 8배의 크기인 original image resolution을 복구.
Deconvolutional 방식과는 다르게, 제안한 방법은 image classification network를 추가적인 parameter를 학습시키는 과정 없이 dense feature extractor로 바꾼다. 그러므로 실전에서 DCNN이 빠르게 학습이 될 수 있음.
Atrous convolution은 arbitrary 하게 filter가 수용하는 영역을 넓혀 버린다. SOTA DCNN (당시 vgg나 resnet) 구조를 보면 computation과 parameter를 줄이기 위해 크기의 커널들로 conv를 진행. Atrous conv는 넓은 receptive field를 사용하되 만큼 띄어서 parameter를 적용한다 (receptive field에서 parameter가 없는 부분은 0으로 채움). 결국 넓은 receptive field를 고려하면서 parameter의 증가는 없다! 실험적으로도 좋은 성능을 보였음.
그 다음에는 효율적인 구현 방법에 대해 나와있는데, 요즘은 TensorFlow나 PyTorch내에 API로 제공이 다 되서 딱히…
Multiscale Image Representations using Atrous Spatial Pyramid Pooling
먼저 semantic segmentation에서 scale의 다양성을 처리하는 두 가지 방법에 대해 실험 해봄.
- 첫번째로 단순한 multiscale processing –> multi-scale로 DCNN을 통해 병렬적으로 score map을 뽑음 –> 각 score map에 대해 bilinear interpolation 적용하고 퓨젼 시킴 (퓨전은 각 point가 multi-scale 중에서 가장 maximum 값을 가지는 걸 가져옴 ) –> 잘 됨, 근데 computing cost가 오져버림
- 두번째 방법은 R-CNN의 spatial pyramid pooling에서 영감을 얻음 –> 이걸 atrous conv로 구현한게 “Atrous Spatial Pyramid Pooling” (ASPP), 아래 그림과 같음
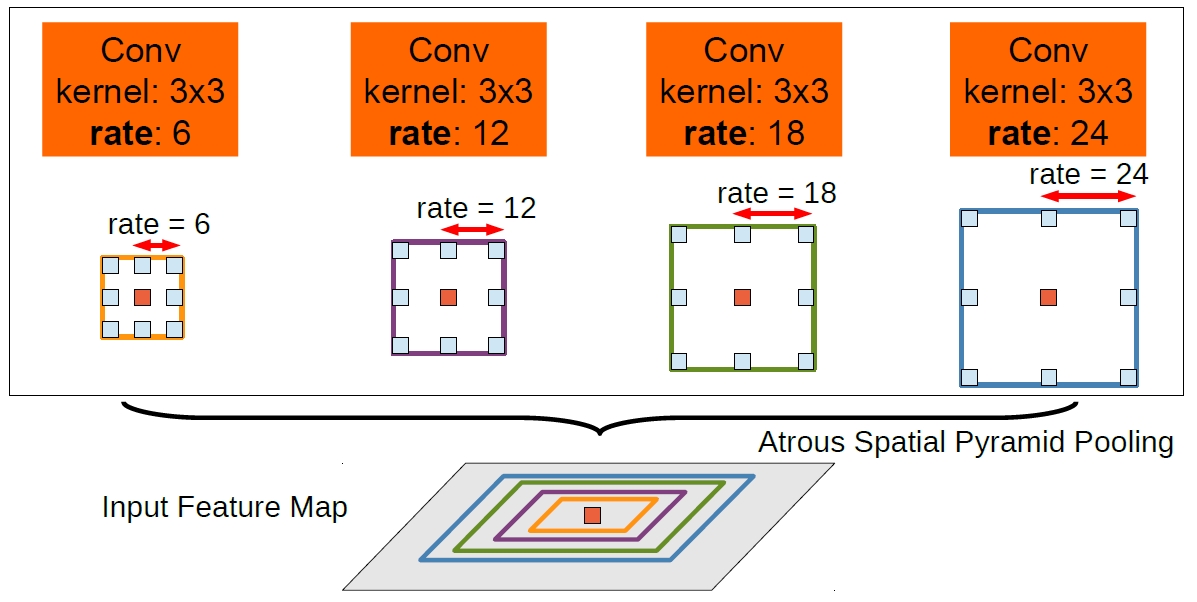
다양한 rate로 뽑힌 feature들을 가지고 pyramid 형태를 구성…
Structured Prediction with Fully-Connected Conditional Random Fields Accurate Boundary Recovery
Localization accuracy와 classification performance 는 trade-off 관계:
- 망이 깊어져서 max-pooling을 여러번 거치면 더 high-level feature가 나오므로 classification에는 유리하지만,
- 그만큼 spatial한 정보들은 많이 잃게 되어 localization에는 불리하게 된다.
아래 그림을 보면 DCNN score map(마지막에 softmax 하기전) rough하게는 object의 위치를 찾을 수는 있으나, 진짜 object의 경계는 그릴 수가 없다.
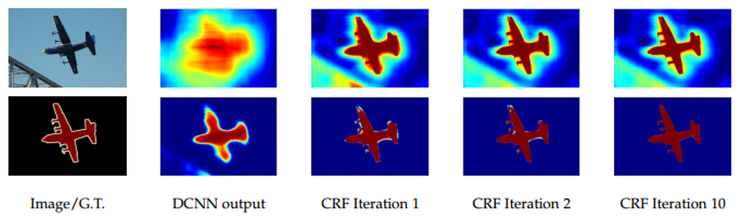
그림을 설명하자면 첫번째 행은 score map(softmax 하기 전), 두번째 행은 belief map(softmax 한 후)
기존 work에서 localization 문제 해결을 위해 크게 두 가지 방법을 추구해왔음:
- 더 나은 object의 경계를 추정하기 위해 conv layer내 여러 layer의 정보를 이용하는 방법
- Super-pixel representation을 이용 –> 기본적으로 low-level의 segmentation 기법으로 localization task를 대체하는 것
여기서는 DCNN의 recognition 능력과 fully connected CRFs의 정제된 localization 정확도를 결합하는 걸 추구했고, 그결과 상당히 성공적으로 localization 문제가 풀렸다! (디테일들이 많이 살아난 것을 확인 할 수 있음)
전통적으로, conditional random fields (CRFs) 은 noisy한 segmentation map을 부드럽게 하는데에 사용 되어왔다:
- 일반적으로 이런 모델들은 인접한 이웃 노드들을 결합하여, favoring same label들의 배치가 공간적으로 중앙 픽셀에 위치하게끔…
- 정성적으로, 이런 short-range CRFs의 기본 function은 hand-crafted feature 기반의 후진 classifier의 잘못된 prediction들을 지워버리는 것.
전통적인 후진 classifier들과 비교할때 DCNN은 매우 좋은 결과를 가져온다. 그렇기 때문에 short-range CRFs를 사용하는 것은 오히려 해가 될수 있다. 우린 좀 더 smooth 시키는 걸 목적으로 해야한다.
Long-range CRFs와 결합하여 constrast-sensitive potential 을 사용하는 것은 localization을 잠재적으로 개선할 수 있찌만 여전히 얇은 structure에서 잘 안되고 일반적으로 상당히 expensive한 discrete optimization 문제 해결을 요구한다.
뭐 이런 short-range CRFs의 한계점을 극복하기 위해, 지네 시스템에 fully connected CRF 모델을 결합함.
이 모델은 다음과 같은 energy function을 사용함:
는 픽셀들에 대한 label. 여기서는 또 unary potential 을 사용하는데, 여기서 는 DCNN을 통해 출력된 픽셀들의 확률 값.
Pairwise potential은 이미지 픽셀들의 모든 pair을 연결하는 방식 보다 더 효율적인 inference가 되게끔 하는 방식이다:
이면 이고, 이면 , 하이퍼 파라미터 는 gaussian kernel의 정도를 조정.
정리하자면…
이 논문의 novelty는:
- atrous conv를 사용한것
- ASPP를 사용한것
- fully-connected CRFs를 사용한 것이다.
Atrous + bilinear interpolation 만으로도 좋은 결과를 가져온다는게 신기허다.